
 あとで読む
あとで読む

構造化データ。
馴染みはあるでしょうか?
私はよくわからないまま、とりあえずソースコードに記述した、というのが始まりでした。そしてSchema.orgの構造化データとGoogle検索セントラルのドキュメントの間で若干迷いました。
この記事は、構造化データをマークアップすることに関連した、ちょっぴり技術寄りのお話です。
何から手を付けたらいいんだ?という時のヒントに、また、道標代わりに、私の思うマークアップの進め方と小さな発見を記します。
構造化データはある程度わかるよ!という方には、おそらく退屈な話になります。(不慣れだとこうなるんだなーという参考くらいにはなるかも?)
ちなみに実際のマークアップ例が書いてあるわけではありません。そちらを期待されていた方、ごめんなさい。
こんな話をしていきます▼
主な参照▼
Google 検索セントラル 検索ギャラリーを見る
Schema.org ドキュメント
さて、構造化データはSchema.orgが定義しています。
そして構造化データは「ここはこの属性、この内容ですよー」とGoogleに伝えるのに使われています。
Googleは「こんなページならこれ書いて」と明示しているので、あとはそれに合わせて内容を詰めるだけ。
ではなぜGoogleはそんな指定をしているのか?
それは、Googleがページの内容を把握しやすくなり、その内容によっては検索結果を専用の表示形態で出せるように、ですね。リッチリザルトといわれています。(※構造化データが検索結果に表示されるとは限りません。)
つまりGoogle検索用構造化データ=リッチリザルト用ともいえるでしょう。
検索結果の表示専用枠があるので目立つという点から、構造化データはSEOの一環と捉えられることもあります。
SEOの視点なら(プレミアム限定)▼
【プレミアム】あなたのサイトで構造化データを導入すべきか否かの判断基準について
では構造化データを入れてみよう、と思われた方も多いでしょう。
最初の一歩として、構造化データとGoogle検索用の構造化データ、違いは大丈夫でしょうか?
私はこの境界が曖昧だったために、こんがらがったのでした。
どうしてか。
(ここからはソースコードを見たことがある前提で進みます。)
構造化データのコード、書き出しは決まって {なんですよね。
"@context": "https://schema.org/",
"@type": ...
そうかそうか、この@typeというのが内容を表していて、いろんな種類があるのだな、と、私はまず思いました。(以降、このTypeを種類と呼んでいます。)
ここまではあながち間違いではないでしょう。
しかし「構造化データというものがあって、Google検索に有効らしい」と初めて聞いた時、なるほどページの内容を構造化データの種類のどれかにあてはめればよいのね、と勝手に解釈しました。
実はもうこの時点でズレ始めています。
Google検索セントラルの「検索ギャラリーを見る」に、構造化データの定義はSchema.orgのドキュメントを参照しろ、と書いてあったので、私は見ました。
なんだか種類がたくさんあります。その分類だか階層だかを見ても、うーん、印象だけは確かに「構造」だね、って具合です。でも勝手に、個々の種類が独立している、とでもいいますか、構造化データの階層を系統図のように単純なものだと思っていました。
大きな間違いです。
構造化データの種類は、単純に独立して存在しているわけではありません。階層はありますが、それぞれが複雑に関係しあっています。というより、きちんとした定義のもとで情報に合った階層構成を組み立てられるからこそ、構造化データたるものでしょう。
私は、とにかくページ内容を表す構造化データの種類を書く⇒Googleが受け入れてくれる
だと勘違いしていたのですが、
Google検索用の構造化データを書く⇒Googleリッチリザルトとして受け付けられる
が正解だったのです。
よしんば自分でがんばって構造化データの種類を書き込んでも、Google検索用の構造化データに当てはまらなければ無駄足です。
そう、Google検索用の構造化データでなくては意味がないのです。
Googleは構造化データ(のボキャブラリ)を使って、検索用の構造化データの定型様式を造り、これならリッチリザルトになるよ、と私たちに提示しているのです。
では改めて基本を抑えていきましょう。

繰り返しになりますが、ここでの目的は、「Google検索用」の構造化データです。
検索用の構造化データについて書かれたGoogle検索セントラルでは、「検索ギャラリーを見る」の「機能」一覧にいくつか項目が並んでいます。この項目ごとにそれぞれのリッチリザルト、検索結果表示に対応しています。ここではそのイメージから、機能項目を『部門』と呼ぶことにします。
検索用に用意された各部門では、「この部門では構造化データのこの種類が必須・推奨項目だよ」と『定型様式』を提示しています。例えるなら、検索結果表示で優遇してもらうためのエントリーシートみたいなもので、名前や特技を書くように、構造化データの特定の種類に対して内容を記入します。定型様式なので、階層構成も定められています。
くどいようですが、勝手に、うちのページ内容だと正確には構造化データのこの種類でこの階層構成だろう、なんて独断で選んで書くと、部門の定型様式と異なり受け付けてもらえず、Google検索用には意味がありません。
検索用の構造化データでは主に schema.org のボキャブラリが使用されていますが、Google 検索の動作の定義には、schema.org のドキュメントではなく Google 検索セントラルのドキュメントを使用してください。
引用:Google 検索セントラル「構造化データの仕組みについて」
正に本質がここにあったのでした。
当然といえば当然ですが、Google 検索セントラルのドキュメントに挙がっている部門の定型様式に必ず合わせましょう。
そして私は素通りしてしまっていたのですが、ちゃんと書いてあったのです、「schema.orgの『ボキャブラリ』」と。
ボキャブラリ、つまり「ことば」の定義がなされているのがSchema.org。いうなれば、構造化データ『辞典』です。
(実はSchema.orgにも書いてあるんですけどね、ボキャブラリ。これも後になってようやく気づいた私です。)
種類だ種類だと思ってきましたが、いえ、確かにたくさんの種類のボキャブラリなのですが、種類という選ぶものより、ボキャブラリだと使うもの、という印象が強くなりました。目から鱗。(気づくのがここまで遅いのは私だけかもですが。)
上級者は辞典そのものを楽しめますが、一般的に、辞典はことばの意味や用法がわからない時に活躍します。Schema.orgは、この構造化データの中身はこれでよいのか、などという疑問があった時、調べるものとして使いましょう。
ページの内容=構造化データの種類ではなく、Google検索用の『部門』に当てはめ、定型様式通りに書く。
その上で補助的に、Schema.orgという『辞典』で調べる。
この基本を忘れなければ、迷わずに行けるでしょう。
基本を抑えたら、次は準備とマークアップといきましょう。
サイト構成を大きく3つに分けて見ていきます。
・パンくずリスト
・サイトのメインカテゴリー
・その他のページたち
これら3つについて、Googleにアピールする優先度が高いのか、補助的に構造化データを入れるのか割り振ってみましょう。
区分イメージはこんな感じです。
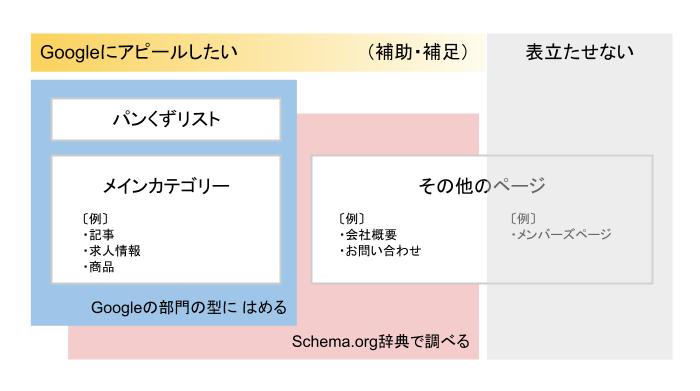
パンくずリストについてはもう明確でしょう。
次に、Googleにアピールしたいカテゴリーがどの部門に当てはまるのかを探しましょう。
▼Google検索用の部門
(出典:Google 検索セントラル「検索ギャラリーを見る」から一部抜粋。順不同。2022/3/14現在のもの)
わかりやすいやつから特殊なものまで、なかなかに個性的なラインナップです。(と私は思います。)
「COVID-19(ベータ版)」が追加されたことからもわかりますが、変化していくものなので、最新のものをチェックするようにしましょう。また、英語のみ対応、などという部門もありますから、説明をよく読みましょう。
蛇足ですが以前「求人情報(JobPosting)」をやろうとした時、Googleの一覧を見て、JobPostingが英語だからか、とにかく目に入りませんでした。今よりもっとデジタル不慣れだった当時の私は、「ないのか、Google?! どこを見るんだ?」と、しばし迷走しました。
そんな時のために『検索窓』というものが画面右上にあるのでした。候補が見当たらない時は、検索してみてください。(はい、とっくに使ってる?…失礼しました。)
検索してもピンとこず、どの部門なのか悩んだ場合は、同業種のサイトが参考になるかもしれません。こっそりサイトを訪れて、ソースコードを見てみましょう。
ついでに「検索ギャラリーを見る」ページでは、「ウェブサイトを表すカテゴリを選択してください」で、部門候補を絞り込むことができます。目立たないし、そこまででもない…と思ってしまったのは私だけでしょうか。
それでは部門が決定したら、そこから入りましょう。
検索ギャラリーを見るページの機能一覧(または左メニューの機能ガイド一覧)のリンクから、該当する部門の「スタートガイド」を参照し、Googleの定型様式通りにマークアップして、規定に沿うようにします。
階層構成や構造化データの種類指定だけでなく、内容の約束事もありますので、ドキュメントをよく読むようにしましょう。
例えば、Article 部門。
AMPと非AMPページで必須・推奨項目が異なります。
特にpublisherはAMPの必須項目となっています。もちろん非AMPページに書いてあっても補足情報となり、損はないでしょう。
しかしpublisherのlogoに注目すると、AMPの場合、画像サイズが決まっています。指定サイズでなくても構造化データから見れば間違いではありません。でもGoogle側から見ると、規定と違う、となってしまいます。
また、Googleは
ページの読者に表示されないコンテンツをマークアップしないでください。
引用:Google 検索セントラル「構造化データに関する一般的なガイドライン」
と言っています。
Articleの例でいえば、公開日などを表示していなかった場合は表示するように変更したほうが無難でしょう。
例えばついでに、もう一つ。
Articleのauthorに関して、マスコットキャラが書いている設定だったとしましょう。
これはPersonなのか、所属のOrganizationにすべきか。
悩んだら、こういう時こそSchema.orgです。
ここでも検索窓を使いましょう。(英語ですが、ひるんではいけません。Chromeだったらブラウザの翻訳ボタンを押せば、説明は日本語に。便利。たまに変だけど。)
いわく、「Person:人(生きている、死んでいる、アンデッド、または架空の)」。
架空=マスコットキャラでもよい、ということがわかります。…ちょっとアンデッドは空恐ろしい気もしますが。
Googleは、
schema.org には Google 検索では不要な属性やオブジェクトもありますが、他のサービス、ツール、プラットフォームで役立つ場合もあります。
引用:Google 検索セントラル「構造化データの仕組みについて」
とか、
コンテンツを公開しているサイトの背景情報(著者ページへのリンクやサイトの概要ページなど)など、掲載されている情報が信頼性の高いものであることを示すための情報を提供しているか
引用:Google 検索セントラル ブログ「Google のコア アップデートについてサイト所有者が知っておくべきこと」
は大事だ、と述べています。余裕があれば、マークアップしてみるのもよいでしょう。(ステップ1をこなした後であれば、きっと力もついているはず。)
補足情報を入れる場合は2つのパターンがあるでしょう。
(1)は気が向いたらやるくらいでよいと個人的には思います。
(2)については、情報源として有益に働きそうです。
ここでSchema.orgを覗いてみましょう。
基本やステップ1では、散々Schema.orgは調べるためだけに使うと言ってきましたが、ステップ2では手のひらを返したように、Schema.orgで、あてはまる種類を探すことにしたいと思います。
ここで述べる構造化データの「種類」とは、Schema.orgの「Type」を指すと思ってください。
サイトの「他のページ」にあてはまりそうな種類ですから、「ウェブページ」グループを見てみましょう。
▼Schema.org「WebPage(ウェブページ)」の、より具体的なType
(出典元:A Schema.org Type「WebPage」2022/3/14現在のもの。※変更される可能性があるので最新をチェックしてください。)
※はGoogle検索用の部門に挙げられています。
中でも★印を付けたAboutPageやContactPageは役に立ちそうです。
それぞれのプロパティの中から項目を選んで書くことになりますが、これが悲しいかな、マークアップ例が載っている構造化データ種類もあるのに、記載なしの種類もあるのです。
でも諦めるのはまだ早い。そういう時は、一つ上の階層WebPageを見ましょう。もともとこのWebPageを更に細かく分類したものが上の一覧になります。
親が使うプロパティを子も使っていたりします。確認して同じものがあれば、親の例を真似て書いてみるとよいかもしれません。
また、プラグインによってはマークアップしてくれるものもありますので、WordPressを使ったサイトなどは検討されてみてはいかがでしょうか。
なるほどこの種類はこういう使い方か、と勉強になることも。(白状すると、上の★印2つはプラグインの受け売りです。使ったプラグインについてはステップ3で紹介しています。)
余談ですがもしかすると、Google検索用の部門にはないんだけど、そしてGoogle検索用としては意味を成さないことを承知しているけれど、情報としては出しておきたい、という場合があるかもしれません。(本当にそんな場合があるかは不明です。)
例えば、製品ページ。Google検索用の部門「Product」の定義に、出したい情報がはまらない、という場合だったとしたら、(Google検索用としては働かないだろうということを織り込み済みで)私なら構造化データの種類は「ItemPage」を使う選択をすると思います。
ただし、個人的な意見なので正直確証はありません。それでもあえてGoogle検索用の部門ではない所を狙ってみる、というのも、事実狙っているのだとしたら価値はあるのかもと私は思います。
構造化データが正しくマークアップされているか確認するのは大切です。
Google検索セントラル「構造化データをテスト」ページには2つのテストツールが載っています。
この2つの違いはもうお手のものでしょう。
Google検索用の部門の定型様式にちゃんとはまっているかは、リッチリザルトテスト(※ページの構造化データで生成される Google のリッチリザルトを確認するもので、それ以外はテストできません。)、
Schema.orgが定義する構造化データとして正しくマークアップされているかは、スキーマ マークアップ検証ツール、ですね。
皆さん、きちんとされると思うので、ここでは詳細など割愛します。
反対に抜けがちなのが、プラグインなどを使った場合に、出したくない情報が出てしまっていないかという確認です。
プラグインは自動でやってくれるので簡単ですが、出力内容のチェックは必ずしましょう。
出力設定をしたページだけでなく、一応他のページも万遍なく見ることをお勧めします。こんなの出てた、ということがあるかもしれません。
ちなみに私が使ったことのあるWordPressプラグイン『Schema』は、記事カテゴリー一覧ページに「CollectionPage」を出してくれていました。
ほうほう、この種類になるのね、なんて思った一方で、WordPressカテゴリー設定の関係でdescription内容が合っていなかったので、Schemaプラグインの公式サイトを調べ、出力OFFにしました。便利だからといって、丸投げにしてはいけないと学んだのでした。
構造化データの種類とページの一致だけでなく、そのプロパティの中身が合っているかもよく見ましょう。

思い込みばかりの私の道中。こんなふうによくわからないまま構造化データの種類から入ると、「Google検索用に構造化データを入れる」という本筋を見失うかもしれません。
私は迷ったおかげで発見もありましたが、迷わずに行けるに越したことはないでしょう。(この記事を読んで、一緒に迷ったかのように不必要な疲れを感じていらしたら、ごめんなさい。)
最後に道筋のおさらいをしたいと思います。
皆さんの進む、検索用の構造化データマークアップの道が少しでも明るくなりますように。
フロントエンドエンジニア兼サポートエンジニア
業界の経験があるわけでもなく、プログラミングを学んだのも職業訓練(+本+少し教わったぶん)だけ、というのに、縁あって現在の職に。不慣れだからこその何かもあるだろうとのん気に構えている。
デジタルの恩恵にあずかる反面、気質としては紙と鉛筆派。愛用の国語辞典も紙製。車はマニュアル。草花の手入れがてら、眺めてボーっと過ごすタイプ。




